How do researchers manage when they have missing data? One of the initial aims of the Mapping Museums project was to establish an authoritative dataset of all the museums open between 1960 and 2020, and to record information on their location, governance, accreditation status, subject matter, opening and closing dates, and visitor numbers. Having this material would provide the first step in constructing a nuanced, evidence-based history of the development of the museum sector during the period, and so the research team began to compile information from numerous sources: surveys conducted by government bodies, by the Association of Independent Museums, and the Museums Association; lists of museums held by the national organisations for the arts; guidebooks; and websites. The researchers also got in touch with dozens of tourist boards and local history groups, and hundreds of curators and volunteers to follow up leads or information. All this material was cross-checked within the team, and then reviewed by experts from the Museum Development Network.
We now have a rigorously researched list of museums in the UK from 1960-2020. Even so, there is still a considerable amount of missing data. When the first phase of data collection was finished we had identified almost 4,000 museums and had established the following coverage of their key attributes:
- Museum opening dates: 88%
- Museum closing dates: 6%
- Governance: 92%
- Visitor numbers: 67%
The question then was, how were we to represent and model the missing dates, governance, and visitor numbers within our analysis?
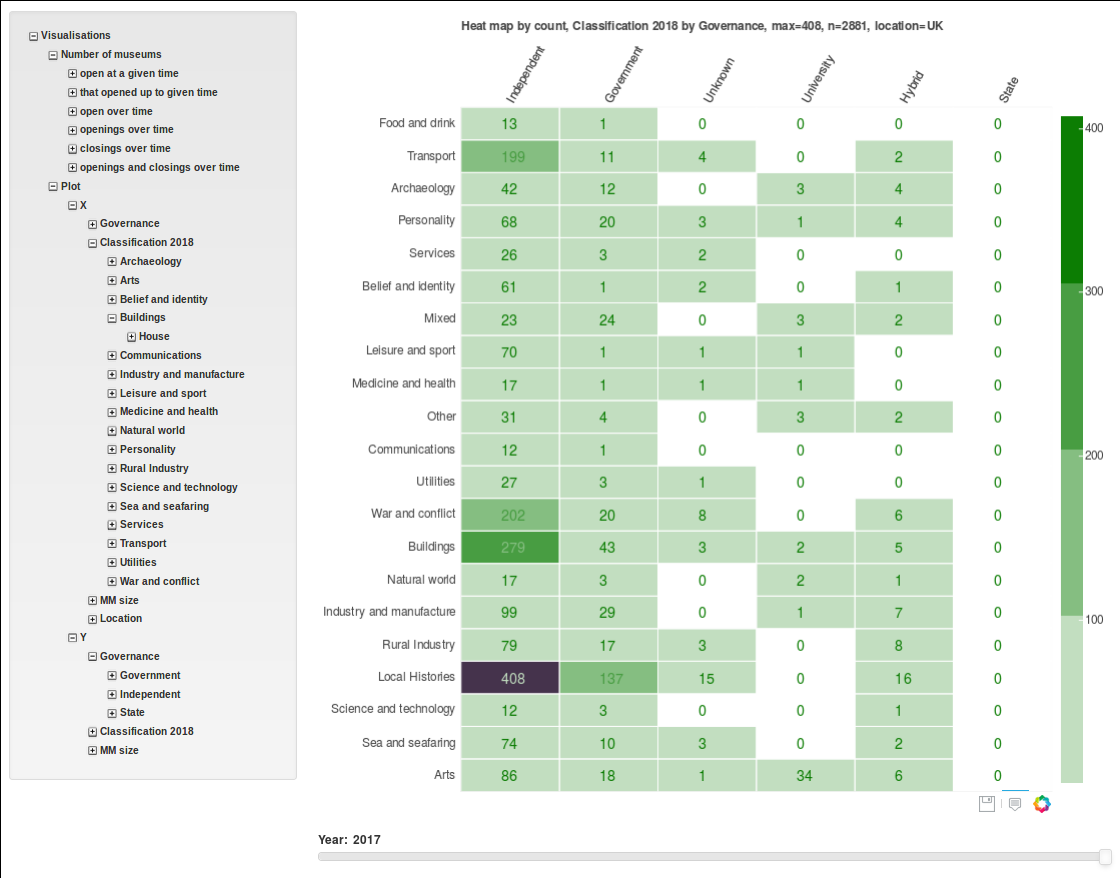
At the same time as collecting data, we started to build a knowledge base that allows users to explore. The system is designed so that users can browse in a structured way through the categories of accreditation, governance, location, size, subject classification, year of opening and year of closing, and see the results on a map or in a list view. Alternatively, they can submit a detailed search that allows them to filter results by combinations of the categories above, or they can generate visualisations of how the different types of museums have emerged over time and create tables showing how the various categories inter-relate. At any point, it is possible to scrutinise the details of individual venues.
One option for dealing with missing information was to exclude museums with missing data from the relevant searches. The problem with that approach is that incomplete data tends to be associated with small, unaccredited museums or with museums that have since closed and so excluding them on this basis would bias our analysis in favour of extant established museums., which would be counter to the purposes of the project as a whole. Thus, when we could not identify a museum’s governance, we assigned it a value of Unknown. The advantage of an explicit Unknown category is that the missing data is made apparent, and the problem of data patchiness is exposed rather than hidden.
We took a different approach to opening and closing dates because we often had rough information about these rather than no information at all – for example, we might know that a museum had closed at some point in the 1990s. This approximate information would be lost if we just categorised a date as ‘unknown’. Therefore, we decided to use a date range of the form (earliest possible year, latest possible year) to capture imprecise knowledge about museum opening/closing dates. These date ranges are used in different ways across the different facilities provided by our system:
- In the Browse facility, we take museums’ opening/closing dates to be the mid point of the specified date range.
- In the Visualise facility, event occurrences are ‘spread’ equally over a date range. For example, if a museum is known to have opened between 1965 and 1969, then the count of one museum opening is spread over that time period (i.e. a count of 0.2 is assigned to each of the five years 1965, 1966, 1967, 1968, 1969).
- In the Search facility, the user has the option of searching by definite dates so that the results exclude all the museums with date ranges attached, or by possible dates, in which case the results include museums where the date range intersects with the specified period. This allows for a much more nuanced analysis.
Looking in more detail at how Search works, opening and closing dates are stored as a pair of years (f,t) in our database, where f and t may be the same year if we know the year of opening/closing for certain. So, for example, the pair (1965,1969) would be stored for a museum known to have opened between 1965 and 1969; and the pair (2011,2011) would be stored for a museum known to have closed in 2011. Modal Logic operators are supported by our system’s Search facility that allow the user to query whether a particular museum definitely or possibly opened/closed in a given year. In particular, suppose a given museum ‘m’ is recorded as having opened in year ‘f’ at the earliest and year ‘t’ at the latest. Suppose a researcher wishes to find out whether museum m opened before, on, or after a specified year ‘d’. Then the following comparison operators are supported by our system to allow the researcher to determine whether this is definitely the case:
| Comparison operator |
Implementation logic |
| (f,t) = d DEFINITELY ON A SPECIFIC YEAR |
f = d and t = d |
| (f,t) < d DEFINITELY BEFORE |
t < d |
| (f,t) <= d DEFINITELY BEFORE OR INCLUDING |
t <= d |
| (f,t) > d DEFINITELY AFTER |
f > d |
| (f,t) >= d DEFINITELY AFTER OR INCLUDING |
f >= d |
| (f,t) != d DEFINITELY APART FROM |
t < d OR f > d |
And the following comparison operators are supported to allow the researcher to determine whether this is possibly the case:
| Comparison operator |
Implementation logic |
| (f,t) = d POSSIBLY ON A SPECIFIC YEAR |
f <= d AND d <= t |
| (f,t) < d POSSIBLY BEFORE |
f < d |
| (f,t) <= d POSSIBLY BEFORE OR INCLUDING |
f <= d |
| (f,t) > d POSSIBLY AFTER |
t > d |
| (f,t) >= d POSSIBLY AFTER OR INCLUDING |
t >= d |
| (f,t) != d POSSIBLY APART FROM |
not (f=d and t=d) |
The same comparison operators are available for interrogating closing dates.
We employed a further strategy for visitor numbers, which is the least complete category and has discontinuities that make it difficult to compare like with like. Our primary objective was to use visitor number data to provide an indication of the size of the museum and, given the patchiness of the information, we decided to have a category of Unknown and also to gross numbers into size categories of Large, Medium and Small, where large and small also have sub-categories. This approach enabled us to include data from the Association of Independent Museums and Arts Council England who generally provide visitor number ranges rather than precise figures, and to use predicative analysis to establish broad size ranges. It also allowed us to circumvent some of the methodological problems of having figures collected by different means and from across the decades. Users can browse or search according to these size categories, and in addition, they can search according to precise date-stamped visitor numbers where available.
In conclusion, in the Mapping Museums project we have managed data patchiness in a variety of ways: designing a flexible knowledge base that can be modified and added to as required; representing absence rather than ignoring unknown information; using date ranges and providing users with the option of searching by definite or possible dates; and apportioning the probability of an opening/closing event occurrence over the estimated time interval for statistical analysis. Rather than implying that all visitor numbers data are of equal reliability, we created size categories for a large number of museums, and provided the means to search the definite but incomplete data that was available.
Fiona Candlin, Alex Poulovassilis
September 2018